Se valorará
La calidad y la técnica utilizada para generar un modelo
Se analizará la técnica analítica utilizada y se compararán objetivamente los valores reales frente a los valores predichos por el modelo. Para ello, se tendrán en cuenta dos objetivos: minimizar las desviaciones con respecto a los datos reales y evitar las roturas de stock (situación en la que la predicción de unidades vendidas es inferior a la demanda real). Está será la métrica a minimizar:
(0.7 * rRMSE) + (0.3 * (1 - CF)), siendo los mejores trabajos los que consigan los valores más reducidos de dicha métrica.
- CF es el % de casos favorables, definidos como aquellos en los que no se ha incurrido en rotura, es decir, la demanda ha sido igual o inferior a la previsión.
- rRMSE se define como
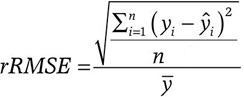
Siendo:
“n” el número de casos,
“yi” el valor real,
“ŷ” el valor estimado,
“Ӯ” la media de los valores reales
¿Qué pedimos?
- Un script (“script exploración”) que contendrá el análisis exploratorio y procesos relevantes testados o ejecutados pero no aplicados en la solución final.
- Un script (“script predicción”) que contendrá el proceso de extracción, transformación y carga de los datos, el procesado aplicado así como la generación de predicciones.
- Una breve descripción donde se expondrá el proceso y la metodología seguida, las técnicas aplicadas y los resultados obtenidos (en formato presentación, pdf o html, máximo 5 páginas con 3 imágenes).
Un valor menor no conllevará explícitamente una mejor clasificación. El “script de predicción” mencionado debe cumplir que sea generalizable y en el caso de métricas equiparables, se tendrán en cuenta los criterios siguientes:
- el Jurado podrá valorar si la documentación interna aportada (código y comentarios) está correctamente estructurada, expresada y es reproducible.
- los scripts de exploración y predicción deben constituir un proyecto de data science con todas sus fases.
En la fase de Presentación y Fallo, el Jurado Nacional tendrá en cuenta, además de los criterios anteriores, que el Proyecto se trasmita de forma clara y concisa.

 Para poder garantizar dicha disponibilidad hay que tener en cuenta dos factores que convierten lo anterior en un reto: no se puede incurrir en rotura de stock (situación en la que la demanda de producto resulta ser superior a las previsiones y se presentan dificultades de abastecimiento en tiempo y forma adecuados) pero tampoco excederse en el aprovisionamiento de unidades de producto con una demanda insuficiente, puesto que requieren un espacio de almacenamiento que es limitado. Por tanto, se necesita una situación de equilibrio que garantice que las desviaciones con respecto a las ventas reales sean mínimas, pero sin incurrir en rotura, puesto que esto tiene impacto directo en la satisfacción de los clientes.
Para poder garantizar dicha disponibilidad hay que tener en cuenta dos factores que convierten lo anterior en un reto: no se puede incurrir en rotura de stock (situación en la que la demanda de producto resulta ser superior a las previsiones y se presentan dificultades de abastecimiento en tiempo y forma adecuados) pero tampoco excederse en el aprovisionamiento de unidades de producto con una demanda insuficiente, puesto que requieren un espacio de almacenamiento que es limitado. Por tanto, se necesita una situación de equilibrio que garantice que las desviaciones con respecto a las ventas reales sean mínimas, pero sin incurrir en rotura, puesto que esto tiene impacto directo en la satisfacción de los clientes. El dataset integra la información de las ventas y atributos de producto para las fechas comprendidas entre 01/06/2015 y el 30/09/2016.
El dataset integra la información de las ventas y atributos de producto para las fechas comprendidas entre 01/06/2015 y el 30/09/2016.