
RETO MINSAIT LAND CLASSIFICATION
idealista nació en 2000 y desde entonces se ha convertido en el principal marketplace inmobiliario del sur de Europa. Desde sus oficinas en Madrid, Barcelona, Málaga, Lisboa y Milán ha sido uno de los principales responsables del cambio de la forma de buscar casa en los mercados que opera y se ha convertido en la herramienta preferida por todos los que buscan alquilar, comprar o vender una casa.
Descubre más en idealista.es.
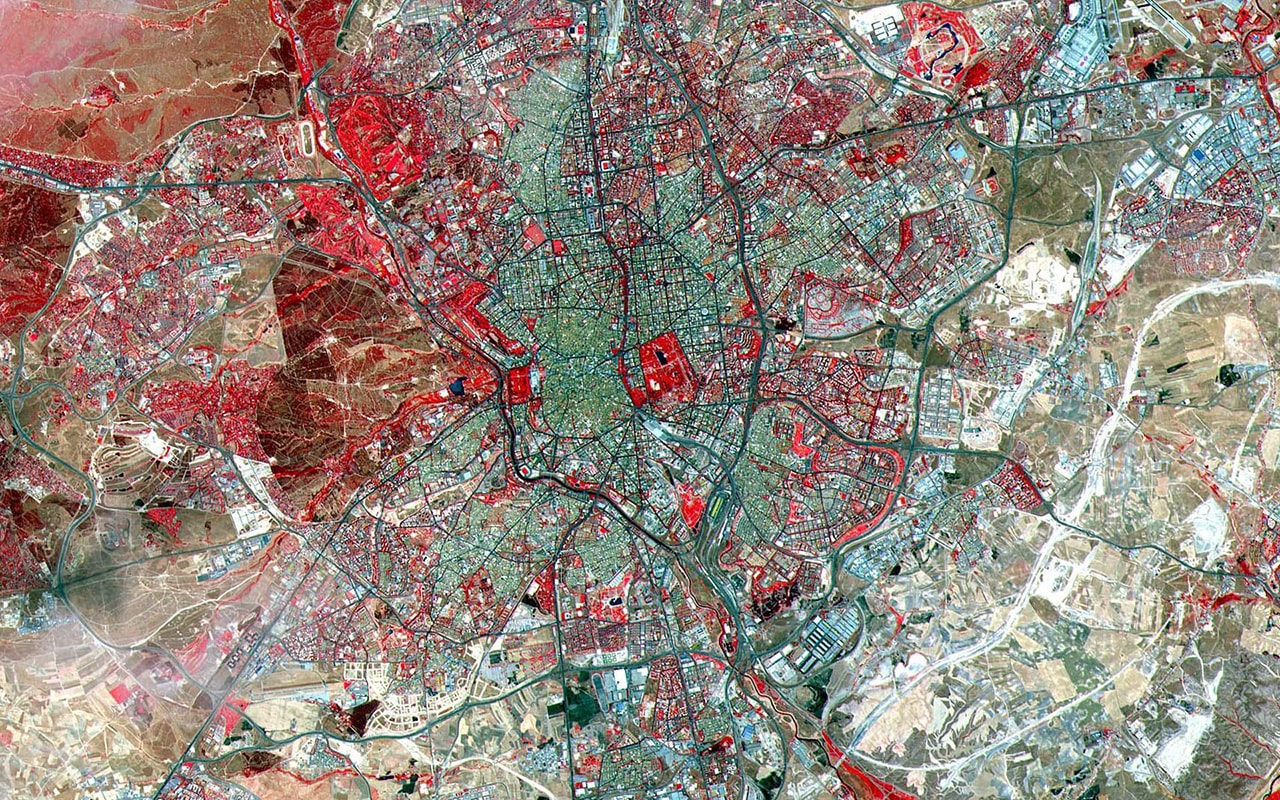
Utiliza la información de las imágenes de satélite para clasificar el suelo.
Actualmente, un gran número de satélites toman imágenes con distintos fines y usos. El gran número de imágenes y la gran cantidad de datos que se obtienen de las mismas hace necesario crear modelos predictivos para identificar el contenido de la imagen.
En este reto ya dispondrás de las variables extraídas de la imagen y georeferenciadas, así como variables categóricas asociadas al entorno para estimar un modelo.
EL OBJETIVO
Te retamos a que encuentres el mejor modelo de clasificación automática de suelos en base a las imágenes proporcionadas por el satélite Sentinel II del servicio Copernicus de la Agencia Espacial Europea.
En este reto dispondrás de un conjunto de fincas catastrales asociados a una lista de atributos extraídos de la imagen.
Para ello puedes utilizar las distintas técnicas de Machine Learning disponibles para este tipo de problemas.
La métrica objetivo a maximizar es la “Exactitud”, (en R, en Python) definida como el “Número de registros correctamente clasificados / Número total de registros proporcionados por la Organización”.
EL DATASET
El dataset contiene un listado de superficies sobre las que se han recortado la imagen de satélite y se han extraído una serie de características de sus geometrías. Finalmente se ha etiquetado el conjunto de los datos según una clasificación de suelo.
Los datos provienen de distintas fuentes, por lo que son datos de tipo tabular.
Ficheros
- Dataset "Modelar_UH2020.txt": Con este fichero deberás construir un modelo predictivo que permita clasificar el uso del suelo en función de las variables proporcionadas. Constará de 103.230 registros.
- Dataset "Estimar_UH2020.txt": El modelo generado lo aplicarás a los datos de este fichero, de modo que calcules, para cada referencia, la clasificación más probable. Constará de 5.618 registros.
Variables
Los ficheros contienen un total 55 variables: las 3 primeras de ellas relativas a la identificación de los registros y las 8 últimas variables son distintas referencias geométricas y relativas al entorno (geometría del edificio, métricas geométricas generadas automáticamente -GEOM-, metros cuadrados, año construcción y nº de plantas de los edificios del entorno).
Las imágenes satelitales se han tratado y se ha extraído información de 4 canales (R, G, B y NIR), correspondientes a las bandas de color rojo, verde y azul, y el infrarrojo cercano. El valor mostrado corresponde a la intensidad por deciles en cada imagen. Estas variables empiezan con la letra “Q”.
El fichero "Modelar_UH2020.txt" tiene, adicionalmente como última variable, la clase a predecir.
Ámbito geográfico y temporal
El ámbito geográfico de las imágenes es una zona concreta del municipio Madrid. La referencia (ID) es distinta y representativa de un elemento diferenciado.

Formato y estructura
Los datasets con formato txt tienen como estructura:
- Nombres de campo: Incluidos en la cabecera.
- Separador: "|".
- Codificación: UTF-8.
Dataset respuesta
Se denominará “Equipo_UH2020.txt” donde Equipo será el nombre del equipo con el que te has inscrito y constará de dos columnas que corresponden a la variable “ID” (identificación de la referencia en “Estimar_UH2020.txt”) y la variable “CLASE”, que la predicción del tipo de terreno estimado por tu modelo.
SE VALORARÁ
- La calidad y la técnica utilizada para generar un modelo
Se analizará la técnica analítica utilizada y se compararán objetivamente los valores reales frente a los valores predichos por el modelo. La métrica para maximizar es la “precisión”. - Comunicación
Que la documentación interna aportada (códigos, comentarios) esté correctamente expresada y estructurada, y sea reproducible. En la Fase de Presentación de mejores trabajos, el Jurado tendrá en cuenta que el modelado y los resultados obtenidos se transmitan de forma clara y concisa.
AYUDAS AL DESARROLLO DEL RETO
De cara a abordar el reto, y centrándonos en los dos principales lenguajes de programación que nos permiten realizar analítica avanzada, Python y R, os mostramos algunas librerías que os pueden servir de ayuda:
-
Librerías en R
dplyr/ data.table
Los paquetes dplyr y data.table son herramientas para la exploración y manipulación de datos.ggplot2
Completo paquete que nos permite representar una gran galería de gráficos. Mejora las funciones habituales de R para gráficos pudiendo incluir más capas y especificaciones.caret
Incluye sencillas herramientas para analizar la calidad de los datos, selección de características, optimización de parámetros o construcción de modelos predictivos.
mlr
Otro de los meta paquetes más populares. Presenta un marco completo para acceder a distintos paquetes de estadística y machine learning de una forma integrada y coherente.
Keras
API para redes neuronales de alto nivel.
Tensor Flow
Interfaz para acceder a la biblioteca de software libre TensorFlow™ que utiliza diagramas de flujo de datos realizar cálculos numéricos.
-
Librerías en Python
Numpy
Manejo de matrices y la realización de operaciones matriciales y vectoriales de forma sencilla y eficiente.Matplotlib
Gráficas muy completas para mostrar los resultados de tus pruebas.Scikit-learn
Librería centrada en machine learning: de clasificadores o regresores, hasta selección automática de modelos y análisis de resultados.