Aggity es una multinacional de tecnología especializada en la Transformación Digital de los negocios combinando las mejores prácticas mundiales y formas operativas con Plataformas Tecnológicas Innovadoras. Con presencia en 20 países, más de 30 años de experiencia en el sector, ofrece una visión transversal del nuevo entorno digital, con soluciones prácticas, tecnológicamente avanzadas y disruptivas. Todas sus plataformas y soluciones utilizan análisis de datos y algoritmos avanzados, aplicando Inteligencia Artificial (incluso GenAI), Cloud, Ciberseguridad y Soluciones Digitales, lo que los convierte en el partner ideal durante de la transformación digital de las empresas en general y de Industria 4.0 en particular, con una visión holística de la cadena de valor.
En una empresa industrial de biotecnología donde se producen antígenos para el desarrollo de vacunas, es de vital importancia optimizar el proceso de producción. Se describe a continuación dicho proceso de producción de una forma generalizada y a alto nivel.
Una vacuna consta de un antígeno (que es el componente activo) y otros componentes (estabilizadores, adyuvantes, excipientes, etc). En este caso nos centramos sólo en la producción del antígeno para un proceso microbiano. Para producirlo, se parte de una pequeña cantidad de un microrganismo, que se multiplica utilizando medios de cultivo y luego se procesa para conseguir el antígeno deseado.
Fases del proceso productivo del antígeno:
Cada tipo de antígeno seguirá un proceso distinto y adecuado a su naturaleza. En general, hay una gran diversidad de procesos productivos según el tipo de antígeno que se desea obtener (bacterias, virus, proteína recombinante, mRNA, VLP, …) por lo que es imposible describir resumidamente todos ellos. Esta diversidad afecta tanto a la expansión del vector biológico (bacteria, células de mamífero, …), lo que se conoce como “upstream”, como a las etapas del proceso de purificación o “downstream”. Una vez se obtiene el antígeno purificado, se puede utilizar para formular la vacuna una vez controlada su calidad según unos parámetros preestablecidos.
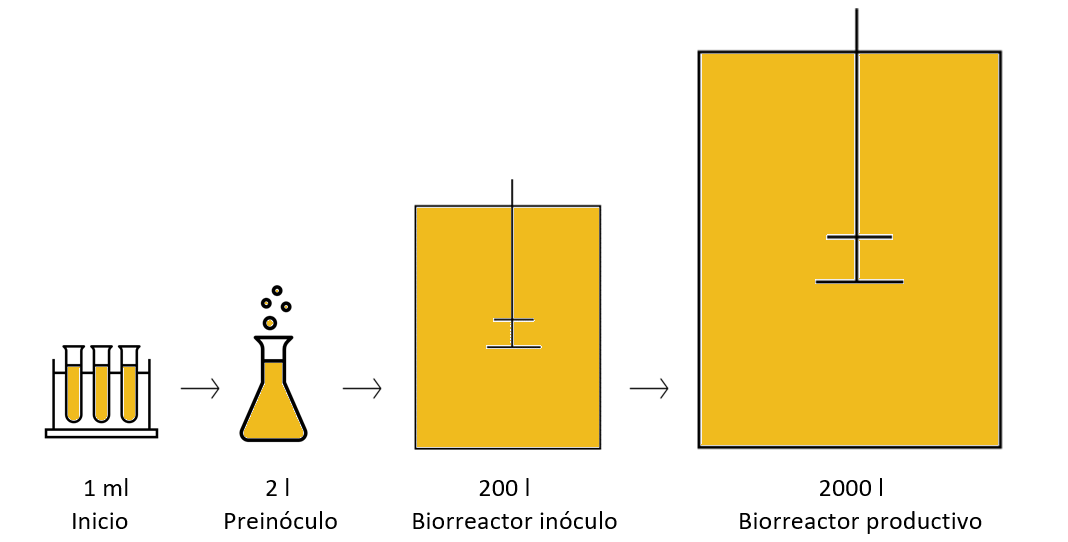
Esquema ejemplo del escalado de volúmenes en un proceso productivo como el descrito anteriormente:
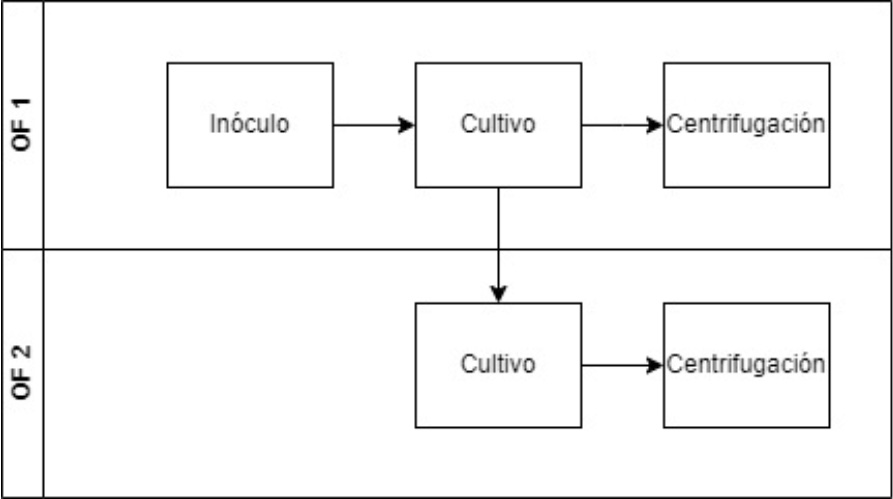
Lotes encadenados: si el título del cultivo es suficiente, una parte del cultivo no se centrifuga, se deja en el mismo biorreactor, y se vuelve a introducir medio de cultivo para iniciar un nuevo cultivo. Este segundo cultivo es una nueva OF, donde los datos de las fases anteriores coincidirán con la OF inicial. Se puede repetir el proceso, mantener una parte del cultivo para una tercera OF. No puede haber una cuarta OF.
Debido al impacto en la sociedad de optimizar y mejorar el proceso, ya que fruto del mismo se desarrollarán mejores vacunas, se hace necesario disponer de una previsión de la concentración del producto en el antígeno final después de todas las fases.
Dado lo anterior y partiendo de amplios datasets de ensayos históricos, te retamos a crear el mejor modelo de predicción de producción que pueda estimar el valor de concentración (producto1) en el antígeno final tras la conclusión de todas las fases descritas el apartado anterior, y de esta forma Identificar los parámetros de proceso que tienen más impacto sobre el título del producto fabricado para mejoras futuras en el proceso.
Los datasets para enfrentar el reto se compartirán al inicio de la fase 1 (local) del calendario de la competición.
El reto hace referencia sólo a cuatro fases del proceso productivo del antígeno de interés:
• Inóculo
• Cultivo productivo
• Centrifugación 1
• Centrifugación 2
Se disponen de datos a tiempo real de cada una de las fases que se quieren analizar, además de datos de los controles de calidad que se realizan en diferentes fases del proceso y sobre el producto resultante.
Se proporcionan dos tipos de tablas de datos: de lote y de evolución. En cualquiera de las tablas, las filas son observaciones y las columnas variables de proceso.
En las tablas de datos de lote, cada fila corresponde a un lote y los valores de las variables describen una propiedad de ese lote en un momento de tiempo concreto, por ejemplo, al final del cultivo o un valor promedio característico de ese lote, por ejemplo, el valor de turbidez obtenido de la centrifugación.
En las tablas de datos de evolución, cada fila corresponde a una observación en un tiempo concreto dentro de la ejecución de un lote. Por lo tanto la tabla está formada por bloques de filas que corresponden a un lote y dentro de cada bloque de filas cada una de ellas representa los valores de las variables de proceso (columnas) en un momento determinado de la evolución del cultivo.

Ponemos a tu disposición los siguientes datasets:
Dataset Información General (OF 123456.xls)
Se define una Orden de Fabricación (OF) para cada producción del antígeno. La OF está compuesta de varias fases, entre las que se encuentran las fases de interés. La OF identifica cada lote que se produce. Para el reto planteado se adjunta información de las OF del antígeno de estudio producidas en los últimos meses.
El antígeno de estudio se identifica con el código 123456. En la tabla “OF 123456” hay el listado de las OF de estudio, las OF o lotes que no estén en esta tabla no se deben tener en cuenta. Esta tabla contiene la siguiente información:
| Campo | Descripción |
| Orden | Identificador de la OF |
| Número de material | Identificador del material, del antígeno producido |
| Texto breve material | Descripción del antígeno |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Cantidad entregada | Volumen de antígeno producido. El reto no trata de maximizar el volumen, sino el título (la calidad) del antígeno |
| Unidad de medida | Unidad de medida (litros) |
Datasets Fases: Preinóculo, Inóculo y Cultivo Final (Fases producción.xls)
En la fase de preinóculo, se hace crecer el mismo microrganismo en 3 frascos diferentes. Para la fase de inoculación, se seleccionan los dos frascos con el pH más bajo, y se utilizan para esta fase. El tercer frasco se desecha.
Los datos de lote para el preinóculo presentes en el dataset son los siguientes:
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Fecha/hora inicio | Fecha de inicio real de la fase |
| Fecha/hora fin | Fecha de fin real de la fase |
| pH línea 1 | Valor del pH del frasco 1 al finalizar la fase |
| pH línea 2 | Valor del pH del frasco 2 al finalizar la fase |
| pH línea 3 | Valor del pH del frasco 3 al finalizar la fase |
| Turbidez línea 1 | Valor de turbidez del frasco 1 al finalizar la fase |
| Turbidez línea 2 | Valor de turbidez del frasco 2 al finalizar la fase |
| Turbidez línea 3 | Valor de turbidez del frasco 3 al finalizar la fase |
| Línea 1 utilizada | Si valor 1, se utiliza frasco 1 para la fase de inoculación |
| Línea 2 utilizada | Si valor 1, se utiliza frasco 2 para la fase de inoculación |
| Línea 3 utilizada | Si valor 1, se utiliza frasco 3 para la fase de inoculación |
Los datos de lote para el inóculo presentes en el dataset son los siguientes:
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| ID biorreactor | Código del biorreactor |
| Fecha/hora inicio | Fecha de inicio real de la fase |
| Fecha/hora fin | Fecha de fin real de la fase |
| Volumen de cultivo | Volumen de medio utilizado durante el cultivo |
| Turbidez inicio cultivo | Turbidez a tiempo 0 |
| Turbidez final cultivo | Turbidez a final de cultivo |
| Viabilidad final cultivo | Indicador de células vivas a final de cultivo |
Los datos de lote para los cultivos productivos presentes en el dataset son los siguientes:
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Orden en el encadenado | Indica la posición relativa de cada lote en una secuencia de encadenados tomando valores de 1, 2 o 3 |
| Lote parental | En caso de ser encadenado, indica cuál es el lote del que es dependiente. Si orden en el encadenado == 1, entonces Lote parental == NA |
| ID biorreactor | Código del biorreactor |
| Fecha/hora inicio | Fecha de inicio real de la fase |
| Fecha/hora fin | Fecha de fin real de la fase |
| Volumen de inóculo | Volumen de inóculo utilizado para iniciar el cultivo. |
| Turbidez inicio cultivo | Turbidez a tiempo 0 |
| Turbidez final cultivo | Turbidez a final de cultivo |
| Viabilidad final cultivo | Indicador de células vivas a final de cultivo |
| ID centrífuga | Código de la centrífuga utilizada para procesar el cultivo |
| Centrifugación 1 turbidez | Turbidez del producto recogido de la primera centrifugación |
| Centrifugación 2 turbidez | Turbidez del producto recogido de la segunda centrifugación |
| Producto 1 | Concentración del producto 1 en el antígeno final después de todas las fases |
| Producto 2 | Concentración del producto 2 en el antígeno final después de todas las fases |
Tanto en la fase de inóculo como en la de cultivos productivos, para relacionar este dataset con los datesets de Biereactores tendremos que hacerlo a partir del ID biorreactor y las fechas/horas de inicio y fin.

Datasets Biorreactores (biorreactor XXXXX.xls)
Los frascos de preinóculo seleccionados se introducen, junto con medio de cultivo, en un biorreactor de pequeño tamaño (códigos 13171, 13172, 14618). Para cada uno de estos equipos hay una tabla de evolución con los valores a tiempo real cada 15 min que contiene las siguientes variables:
| Campo | Descripción |
| DateTime | Fecha y hora de registro de los valores |
| xxx.Agitation_PV | Velocidad de agitación |
| xxx.Air_Sparge_PV | Aporte de aire por sparger |
| xxx.Biocontainer_Pressure_PV | Presión biorreactor |
| xxx.DO_1_PV | Presión parcial oxígeno 1 |
| xxx.DO_2_PV | Presión parcial oxígeno 2 |
| xxx.Gas_Overlay_PV | Aire por cúpula |
| xxx.Load_Cell_Net_PV | Peso |
| xxx.pH_1_PV | pH cultivo |
| xxx.pH_2_PV | pH cultivo |
| xxx.PUMP_1_PV | Adición antiespumante |
| xxx.PUMP_1_TOTAL | Total antiespumante |
| xxx.PUMP_2_PV | Adición solución base |
| xxx.PUMP_2_TOTAL | Total solución base |
| xxx.Single_Use_DO_PV | Presión parcial oxígeno |
| xxx.Single_Use_pH_PV | pH cultivo |
| xxx.Temperatura_PV | Temperatura cultivo |
Una vez completado el crecimiento del inóculo se traspasa el volumen necesario a un Biorreactor de producción (códigos 13169, 13170, 14614, 14615, 14616, 14617). Los datos a tiempo real de estos equipos son los mismos que en los biorreactores de pequeño tamaño (ver tabla anterior).
Dataset Cinéticos IPC (Cinéticos IPC.xls)
Durante el proceso de inóculos, se hacen controles en proceso donde se analizan algunas variables de proceso para determinar la evolución del cultivo (Excel “Cinéticos IPC” pestaña Inóculos):
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Fecha | Fecha y hora que se realiza la observación |
| Turbidez | Valor de turbidez en el momento de la observación |
| Viabilidad | Valor de viabilidad en el momento de la observación |
Durante la fase de cultivo, se hacen controles en proceso donde se analizan algunas variables de proceso para determinar la evolución del cultivo (Excel “Cinéticos IPC” pestaña Cultivos finales):
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Fecha | Fecha y hora que se realiza la observación |
| Turbidez | Valor de turbidez en el momento de la observación |
| Viabilidad | Valor de viabilidad en el momento de la observación |
| Glucosa | Valor de glucosa en el momento de la observación |
Durante la centrifugación, se hacen controles en proceso donde se analizan algunas variables de proceso para determinar la evolución del cultivo (Excel “Cinéticos IPC” pestaña Centrifugación):
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción |
| Centrífuga | Equipo utilizado |
| Centrifugada (1 o 2) | Indica si es la primera o segunda centrifugación |
| Volumen centrifugado | Cantidad de producto centrifugado en el momento de la observación |
| Turbidez | Valor de turbidez en el momento de la observación |
Datasets Fase de Centrifugación (Centrífuga XXXXX.xls / Horas inicio fin centrífugas.xls)
El producto resultante de la fase de cultivo se centrifuga dos veces. Primero se centrifuga todo el cultivo (centrifugación 1), luego se diluye el producto centrifugado y se vuelve a centrifugar (centrifugación 2). Las dos centrifugaciones se realizan en la misma centrífuga. Los códigos de las centrífugas son: 12912, 14246, 17825.
Para cada uno de estos equipos hay una tabla (Centrífuga XXXXX.xls) con los valores a tiempo real cada 15 min que contiene los datos de evolución:
| Campo | Descripción |
| DateTime | Fecha y hora de registro de los valores |
| xxx_CTF0101.EN_Parcial | Número de descargas parciales |
| xxx_CTF0101.EN_Total | Número de descargas totales |
| xxx_D01780551.PV | Apertura válvula agua maniobra |
| xxx_D01906041.PV | Caudal |
| xxx_D01916047.PV | Contrapresión |
| xxx_D01916503.PV | Presión del agua de maniobra |
| xxx_D01919022.PV | Velocidad de separación |
El archivo ”Horas inicio fin centrifugas.xlsx” contiene información sobre los tiempos de inicio/fin de esta fase. Puede haber producciones de otros materiales intercalados que no son OF del material de estudio (123456).
| Campo | Descripción |
| Equipo | Identificador de la centrífuga utilizada |
| Operación | Indica si es un evento de inicio o fin, y si es de la primera centrifugación o de la segunda. |
| Orden | Identificador de la OF |
| DateValue | Fecha y hora en el que se produce el evento de inicio o fin. |

Dataset Materias Primas Utilizadas (Movimientos componentes.xls)
Contiene información sobre las materias primas utilizadas para la producción del medio de cultivo utilizado en las fases de producción. Estas materias primas se compran a proveedor, y se identifican con un Lote de proveedor. Cuando las materias primas se recepcionan en el almacén principal, se les asigna un número de lote interno que lo identifica en los procesos de producción. Un mismo Lote de proveedor puede corresponder a varios Lotes internos si se recepcionan en días diferentes.
Los materiales se almacenan primero en el almacén principal y luego se trasladan al almacén de producción donde se almacenan hasta su uso en producción.
Para un mismo lote participan distintos materiales y de cada material se pueden usar distintos lotes para completar la cantidad necesaria
| Campo | Descripción |
| Lote | Número de lote producido. Igual que el número de OF, la relación de material y lote también identifica cada producción. A través de este campo cruzamos con el resto de datasets |
| Material | Código de la materia prima utilizada |
| Lote interno | Identificador de lote que se genera al recepcionar una mercancía de proveedor. |
| Lote proveedor | Identificador que la da el proveedor a el lote que suministra |
| Qty | Cantidad de producto utilizado |
| Fecha recepción | Fecha en que se recibe el producto del proveedor y se almacena en el almacén principal. |
| Fecha traslado | Fecha que el producto se traslada del almacén principal al almacén de producción. |
Dataset Temperaturas y Humedades (Temperaturas y humedades.xls)
Contiene información respecto a las condiciones ambientales de los almacenes y las salas de producción.
| Campo | Descripción |
| DateTime | Fecha y hora de registro de los valores |
| 06299_TI1302.PV | Temperatura sala biorreactores |
| 06299_MI1302.PV | Humedad sala biorreactores |
| 06299_TI1402.PV | Temperatura sala centrifugas |
| 06299_MI1402.PV | Humedad sala centrifugas |
| 07633_TI0601.PV | Temperatura almacén principal |
| 07633_HI0101.PV | Humedad almacén principal |
| 07781_TI1501.PV | Temperatura almacén producción |
| 07781_MI1501.PV | Humedad almacén producción |
Se proporcionará los mismos datasets que para el entrenamiento acabados en “_test” pero no se dispondrá de los datos producto 1 y producto 2, recordemos que el producto 1 es la variable target del reto.
Es el fichero solicitado con tus predicciones de producción.
Se denominará “Equipo_UH2024.txt” donde ‘Equipo’ será el nombre del equipo con el que te has inscrito.
Sin cabecera ni nombres de filas.
Constará de las mismas filas que la pestaña “cultivo final” del Excel “Fases producción_test.xls” con 2 columnas cada fila:
• LOTE: ordenado de forma ascendente
• PRODUCTO 1: Estimación Concentración del producto 1 en el antígeno final después de todas las fases
Separando campos con “|”y los decimales con “.”.
Además del “dataset respuesta”, te pedimos:
Un valor menor no conllevará explícitamente una mejor clasificación. El “script de predicción” mencionado debe cumplir que sea generalizable y en el caso de métricas equiparables, se tendrán en cuenta los criterios siguientes:
• el Jurado podrá valorar si la documentación interna aportada (código y comentarios) está correctamente estructurada, expresada y es reproducible.
• los scripts de exploración y predicción deben constituir un proyecto de data science con todas sus fases.
La calidad y la técnica utilizada para generar un modelo. Para ello se utilizará como métrica el RMSE que permite comparar objetivamente los valores reales frente a los valores predichos por el modelo, se tendrán que minimizar las desviaciones de los valores obtenidos respecto a los datos reales.
El “error cuadrático medio” o RMSE, definido como:
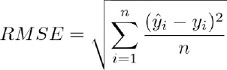
Siendo:
“n” el número de casos,
“ŷ” el valor estimado,
“y” el valor real
Los equipos que participen en la fase nacional se valorarán siguiendo el siguiente criterio. Un primer nivel en función exclusivamente de la métrica, se seleccionarán los 10 trabajos que obtengan las mejores métricas.
Los 10 equipos seleccionados se evaluarán con los siguientes criterios:
En la Presentación y Fallo de mejores trabajos, el Jurado tendrá en cuenta, además de los criterios anteriores, que el Proyecto se transmita de forma clara y concisa y que suponga una solución adecuada al reto a nivel empresarial.
Además del dataset proporcionado, se muestran algunos recursos que podrían ser de interés para la realización del presente reto.
Prophet
Prophet es un procedimiento de pronóstico implementado en R y Python. Es rápido y proporciona pronósticos completamente automatizados que los científicos y analistas de datos pueden ajustar manualmente.
AI Fairness
Conjunto de herramientas extensible de código abierto para examinar, informar y mitigar la discriminación y el sesgo en los modelos de aprendizaje automático a lo largo del ciclo de vida de la aplicación de IA.
Dalex
Herramientas para la explicabilidad de los modelos
dplyr/data.table
Los paquetes dplyr y data.table son herramientas para la exploración y manipulación de datos.
ggplot2
Completo paquete que nos permite representar una gran galería de gráficos. Mejora las funciones habituales de R para gráficos pudiendo incluir más capas y especificaciones.
caret
Incluye sencillas herramientas para analizar la calidad de los datos, selección de características, optimización de parámetros o construcción de modelos predictivos.
mlr
Otro de los meta paquetes más populares. Presenta un marco completo para acceder a distintos paquetes de estadística y machine learning de una forma integrada y coherente.
Tidyverse
Colección de paquetes de R diseñados para data Science.
Keras
API para redes neuronales de alto nivel.
Tensor Flow
Interfaz para acceder a la biblioteca de software libre TensorFlow™ que utiliza diagramas de flujo de datos realizar cálculos numéricos.
iml
Librería con herramientas de interpretación y explicación de modelos.
Series Temporales
Paquetes de R para el análisis de series temporales.
Numpy
Manejo de matrices y la realización de operaciones matriciales y vectoriales de forma sencilla y eficiente.
Matplotlib
Gráficas muy completas para mostrar los resultados de tus pruebas.
Scikit-learn
Librería centrada en machine learning: de clasificadores o regresores, hasta selección automática de modelos y análisis de resultados.
lime
Librería con herramientas de interpretación y explicación de modelos.
